운영체제에는 다양한 페이지 교체 알고리즘이 있다. 페이지 교체 알고리즘이 필요한 이유는 page fault ratio를 낮추기 위해서지만, 근본적인 원인은 메인 메모리의 용량이 한정적이기 때문이다. Page Fault가 발생했는데 메인 메모리가 가득 찼다면 페이지를 교체해야 한다. 여기서 교체 대상이 되는 페이지를 'victim page'라고 한다.
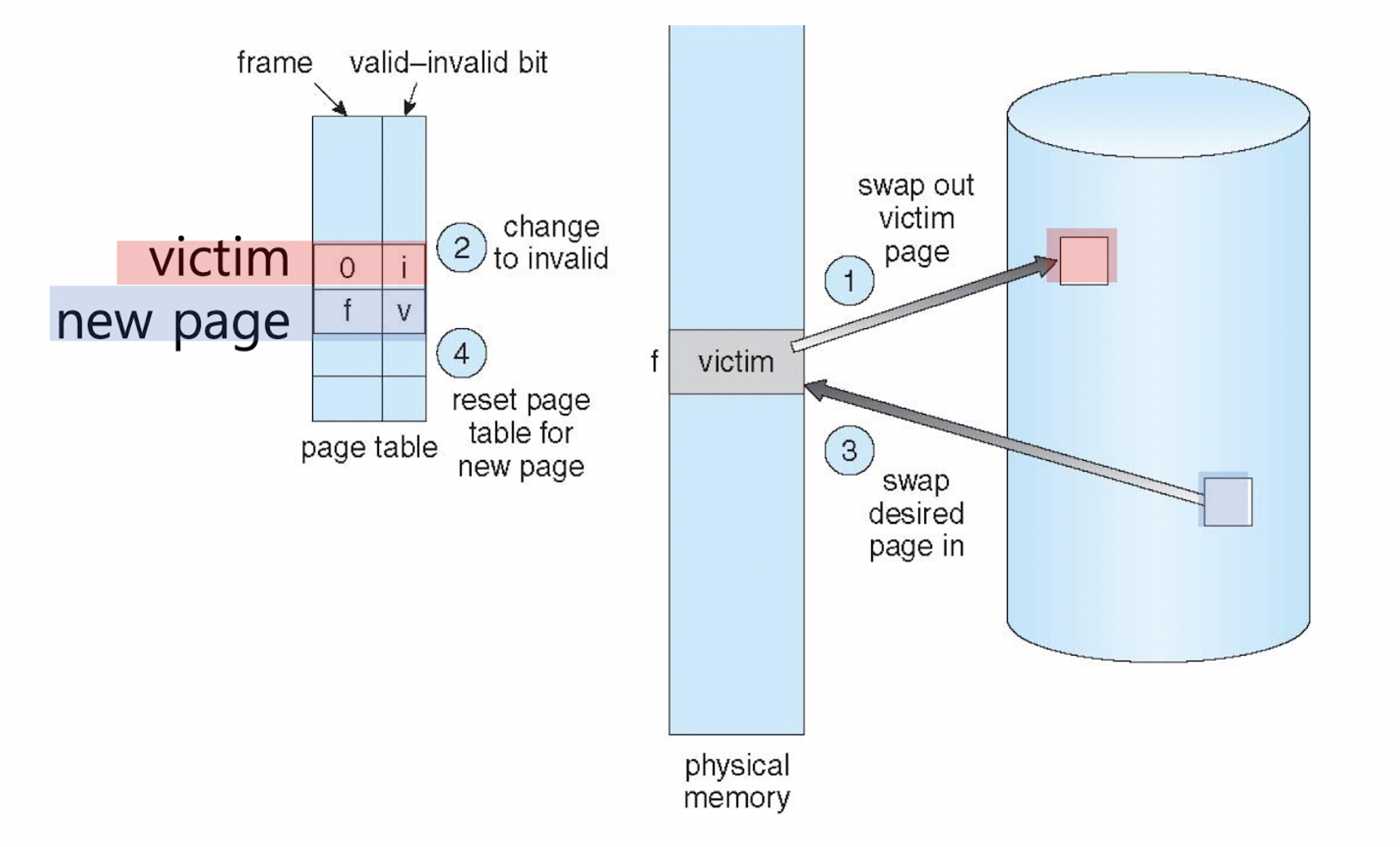
위 그림을 보면 victim 페이지가 SSD에 swap out 되고, 페이지f 가 swap in 됐다. 페이지 테이블에서 valid bit의 변화를 보면 victim 페이지는 i로, 페이지f 는 v로 수정됐다. 즉, victim 페이지는 메인 메모리 상에 없다는 뜻이고, 페이지f 는 메인 메모리 상에 있다는 뜻이다.
Valid bit는 찾고자 하는 페이지가 메인 메모리에 존재하는지 알려주는 값으로, PTE(Page Table Entry)마다 가지고 있다. 사실 PTE에는 정보를 나타내는 비트가 여러개 있는데 valid bit는 단지 그중 하나일 뿐이다. PTE의 구성은 여기서 확인할 수 있다. 이 중에 Modify bit(Dirty bit)를 잠시 짚고 넘어가자.
Modify Bit ( = Dirty Bit )
Page Fault 발생시 free frame이 없는 경우를 자세히 살펴볼 필요가 있다. 약간의 트릭으로 page fault time을 단축시킬 수 있기 때문이다. 페이지가 교체될 때는 swap out 과 swap in 이 일어난다. 그런데 모든 경우마다 그럴 필요가 없다. 특수한 상황에서는 swap out 과정이 필요 없기 때문이다. 특수한 상황이란 어떤 상황을 말하는 것일까?
초기에 SSD에서 메인 메모리로 Page A를 로딩했다고 가정해보자. 만약에 Page A의 내용이 전혀 수정되지 않았다면 Page A가 교체될 때 SSD에 다시 저장할 필요가 있을까? 변경된 내용이 없기 때문에 그럴 필요가 없다. 동일한 내용이 SSD 어딘가에 저장되어 있기 때문이다. 따라서 수정되지 않은 페이지는 swap out 과정이 필요 없다.
만약에 페이지의 수정 여부만 알 수 있다면 페이지 교체시 swap out 시간을 절약할 수 있다. 수정되지 않았으면 swap in만 해주면 되기 때문이다. 이렇게 페이지의 수정 여부를 알려주는 값이 Modify Bit다. 초기값은 0이며, 페이지가 수정되면 1로 바뀐다.
이제 페이지 교체 알고리즘을 본격적으로 살펴보자.
1. First-In-First-Out( FIFO ) Algorithm
말 그대로 할당된 순서대로 교체되는 알고리즘이다. 가장 먼저 할당된 페이지가 1순위가 되며, 그 다음이 2순위, ... 이런식으로 교체된다. 원형큐를 통해 간단히 구현할 수 있다.
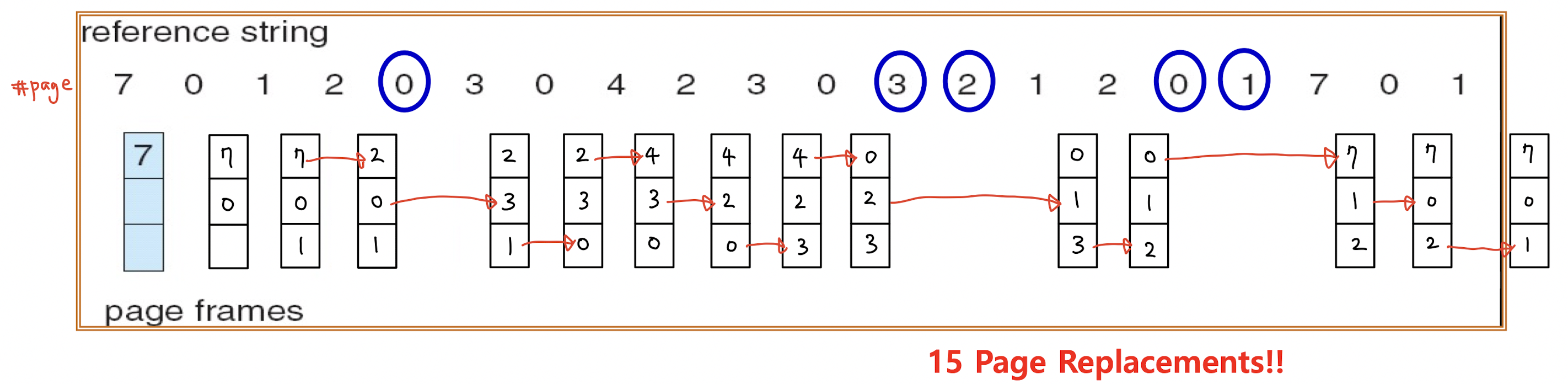
위 그림에서 총 15번의 페이지 교체가 발생했다. 처음 세 번은 free frame이 있어서 바로 할당됐지만 그 이후부터는 다른 페이지가 swap out 되고, 새로운 페이지가 swap in 된 것을 볼 수 있다. FIFO 알고리즘 '가장 오래된 페이지를 교체'하는 방법이다. 그런데 먼저 들어온 페이지가 자주 쓰이는 현상이 충분히 발생할 수 있다. 일반적으로 프레임 개수를 늘리면 page fault의 발생 횟수가 감소하는데, FIFO 알고리즘은 페이지의 최근 참조를 고려하지 않기 때문에 프레임 개수를 늘려도 page fault가 오히려 늘어나는 현상이 발생할 수 있다. 이를 Belady's anomaly 이라고 한다. 아래 그림에서 오른쪽의 프레임 수가 4개로, 왼쪽의 프레임 수보다 많다. 그런데 page fault의 발생 횟수는 왼쪽이 더 작다.

Belady's Anomaly
: 페이지 프레임의 개수를 늘리면 page fault 발생이 감소 해야 하는데, 오히려 늘어나는 현상
2. Optimal Algorithm
앞으로 가장 사용 안 할 페이지를 교체하는 알고리즘이다. 굉장히 이상적이고 page fault ratio가 가장 낮은 알고리즘이다.

위 그림에서 총 9번의 페이지 교체가 발생했다. 화살표가 연결된 프레임 박스만 살펴보자. 세 개의 프레임에 각각 7, 0, 1번 페이지가 들어가있다. 세 개의 페이지 중 가장 나중에 사용되는 페이지는 7번이므로, victim page 7번을 swap out하고 new page 2번을 swap in했다. 완벽한 방법이라고 생각하겠지만, 사실 이 알고리즘은 구현 불가능하다. 왜냐하면 미래에 쓸 페이지들의 순서를 전부 알고 있어야만 구현 가능하기 때문이다. 하지만 CPU가 미래에 어떤 페이지를 요청할지는 알 방법이 없다.
최적화 알고리즘은 미래의 값을 다 알고 있다는 가정이기 때문에 page fault를 최소로 발생시키는 알고리즘이다. 그래서 최적화 알고리즘은 주로 교체 알고리즘 성능의 기준점으로 사용된다. 예를들어 어떤 연구자가 새로운 교체 알고리즘 T를 고안해냈다고 가정해보자. 그러면 알고리즘 T의 page fault 횟수에 최적화 알고리즘의 page fault 횟수를 나눈 값이 알고리즘 T의 성능이 되는 것이다.
3. Least Recently Used(LRU) Algorithm
가장 마지막에 쓴 페이지를 교체하는 알고리즘이다. 과거 이력을 저장해야 하기 때문에 하드웨어의 도움이 필요하다. Counter를 사용하는 방법과 Stack을 사용하는 방법이 있다. 차례대로 알아보자.
1) Counter Implementation
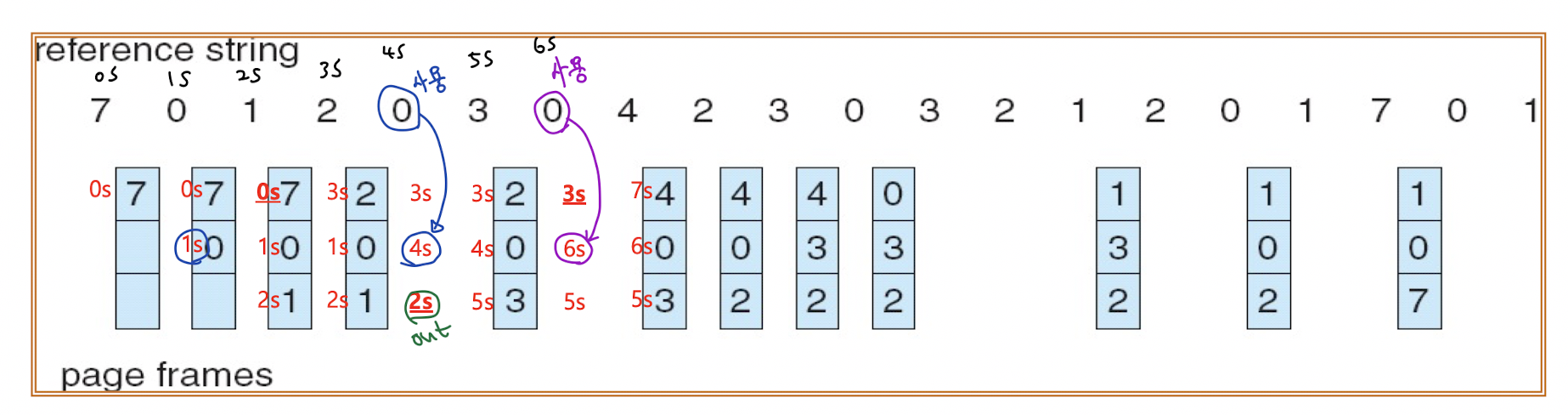
위 그림과 같이 모든 페이지에 counter가 존재한다. Free frame이 있으면 페이지는 그냥 프레임을 할당받으면 된다. Free frame이 없으면 counter 값이 가장 작은 페이지를 교체한다. 페이지가 교체될때마다 Counter 값도 큰 값으로 변하기 때문에 Counter 값이 가장 작다는 것은 가장 오랫동안 사용이 안 된 페이지라는 뜻이다.
그런데 이 방법은 페이지를 교체할때마다 프레임 내의 모든 counter를 탐색해야 하는 단점이 있다. 탐색 시간은 그대로 오버헤드로 이어진다.
2) Stack Implementation
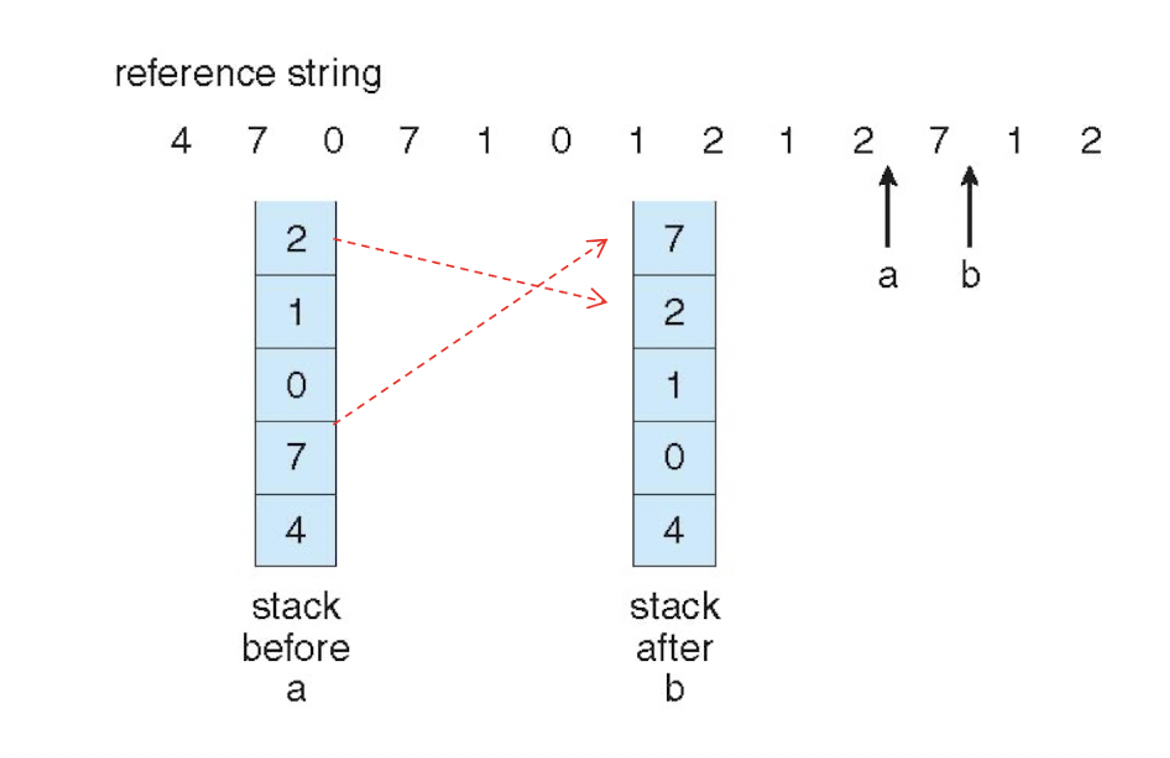
참조 스택을 하나 만들어서 페이지가 사용될때마다 사용한 페이지를 스택의 top에 두는 방법이다. 한번이라도 사용되면 스택의 최상단에 위치하게 되므로 스택의 bottom에 위치한 페이지가 교체 대상이 된다. 왜냐하면 가장 bottom에 위치한다는 것은 그동안 한 번도 사용되지 않았다는 뜻이기 때문이다. 위 그림은 reference string이 a에서 b로 가는 예시다. 즉, a 스택에서 7번 페이지를 참조하면 b 스택이 되는 것이다. a 스택에 7번 페이지가 있기 때문에 b 스택에서 7번은 최상단에 위치하게 된다.
스택은 알다시피 원소 하나를 빼고 넣으려면 위에 있는 모든 원소를 다 빼야 한다. 그래서 스택을 사용할 때 push pop의 효율성을 위해 단순연결리스트를 사용하지 않고 이중연결리스트를 사용한다. 그런데 이중연결리스트는 최악의 경우 포인터가 여섯번이나 수정된다. 이는 자료구조 내용이므로 넘어가도록 한다. 요점은 Stack을 사용한 방법도 비용이 많이 발생한다는 것이다.
Counter 와 Stack으로 구현하는 방법 모두 살펴봤는데 clock 필드와 stack은 메모리를 참조할때마다 업데이트 돼야 하므로 오버헤드가 있다. 이에 대한 대안으로 Second-Chance Algorithm을 사용한다.
3) Second-Chance Algorithm
이 알고리즘은 LRU 알고리즘에 근접한(?) 알고리즘이다. 영어로 LRU Approximation이라고 나와있는데 뭐라고 번역해야할지 모르겠다. LRU를 구현하려고 봤더니 counter와 stack을 사용하는 방법이 있는데, 이 두 방법은 비용이 많이 들어서 좀 더 가벼운 방법을 고안해낸게 Second-Chance 알고리즘이다.
Second-Chance 알고리즘은 참조 비트(Reference bit)를 사용한다. 참조 비트는 모든 page table entry에 존재하며, 페이지가 참조될 때 하드웨어에 의해 설정된다. 참조 비트는 최초 0으로 초기화되어 있으며, 프로세스가 실행되면 참조되는 페이지들의 참조 비트는 1로 설정된다. 이 참조 비트를 통해 페이지의 사용 여부는 알 수 있지만, 페이지가 사용된 순서는 알 수 없다.
Second-Chance 알고리즘은 기본적으로 FIFO 알고리즘에 기반을 둔다. FIFO 알고리즘에 참조 비트를 추가해 최근에 참조했는지 확인하는 알고리즘이 Second-Chance 알고리즘이다. 아까 위에서 FIFO 알고리즘은 원형큐로 간단하게 구현할 수 있다고 했는데 Second-Chance 알고리즘도 마찬가지다. 알고리즘의 기본 규칙은 아래와 같다.
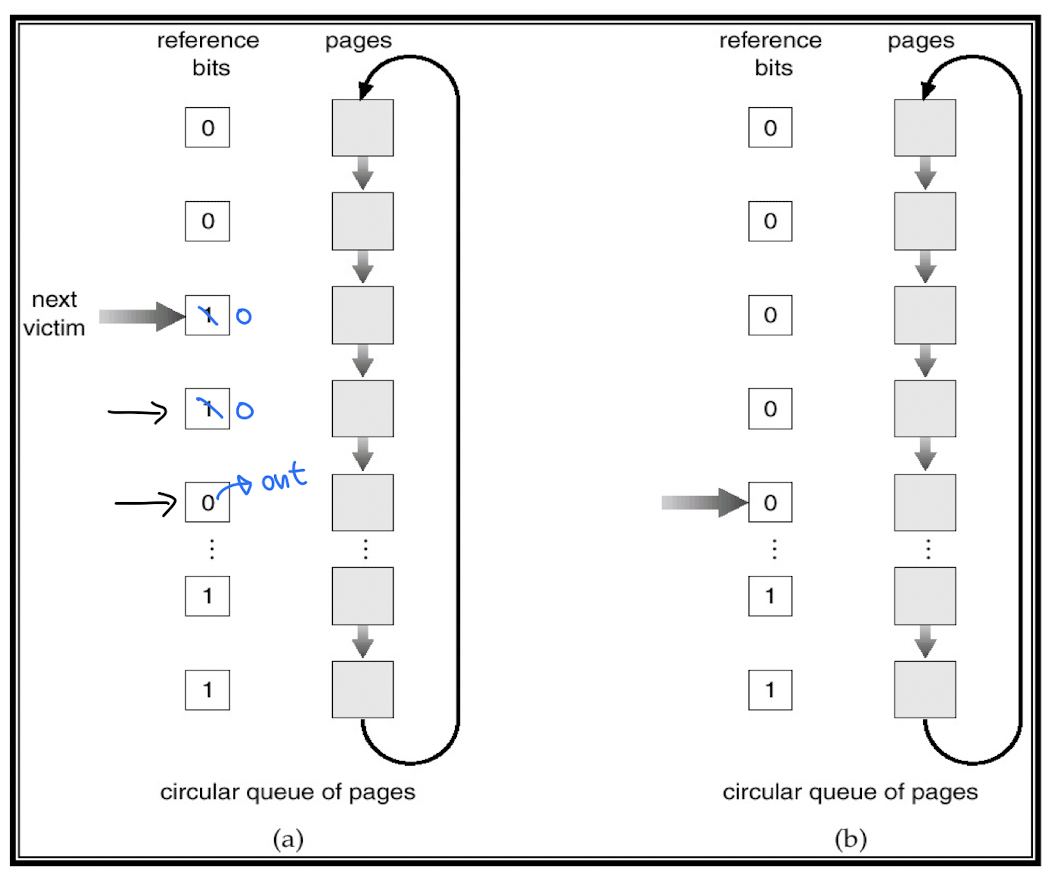
검사할 페이지를 가리키는 포인터 존재
메모리 참조시마다 아래를 검사
1. 참조하는 페이지가 프레임 내에 존재하는 경우 - 해당 프레임의 참조 비트를 1로 수정, 포인터는 그대로
2. 참조하는 페이지가 프레임 내에 존재하지 않는 경우
--- 1) 포인터가 가리킨 페이지의 참조 비트가 0이면 교체, 포인터는 다음칸으로 이동
--- 2) 포인터가 가리킨 페이지의 참조 비트가 1이면 0으로 수정, 포인터는 다음칸으로 이동후 2번 반복 (second chance)
2-1 에서 포인터가 가리킨 페이지가 교체되지 않고 넘어가는 것을 다시 한번 기회를 준다고 표현해서 'second-chance'로 부르는 것이다. 위 알고리즘을 그대로 따라해보는 예제를 풀어보자. 약간 지저분해서 접은글 안에 넣어놨다. 더보기란을 클릭하면 된다.
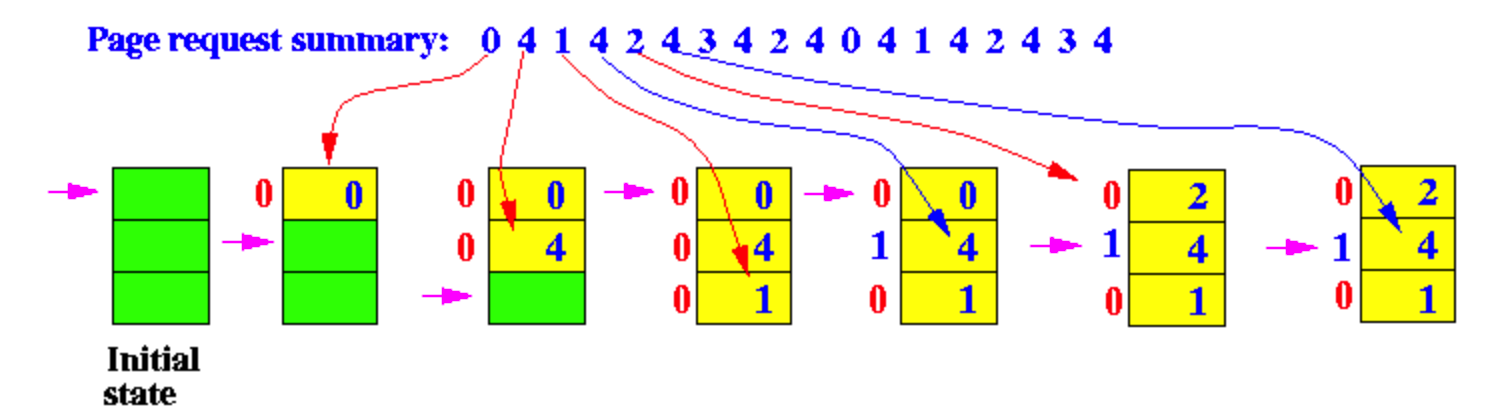
왼쪽부터 차례대로...
1) Initial state 초기에는 빈 프레임
2) 프레임 내에 page0 없으므로 교체해주고, 포인터는 다음칸 이동
3) 프레임 내에 page4 없으므로 교체해주고, 포인터는 다음칸 이동
4) 프레임 내에 page1 없으므로 교체해주고, 포인터는 다음칸 이동
5) 프레임 내에 page4 있으므로, page4 의 참조 비트를 1로 수정, 포인터는 그대로
6) 프레임 내에 page2 없으므로 교체해주고, 포인터는 다음칸 이동
7) 프레임 내에 page4 있으므로, page4 의 참조 비트를 1로 수정, 포인터는 그대로
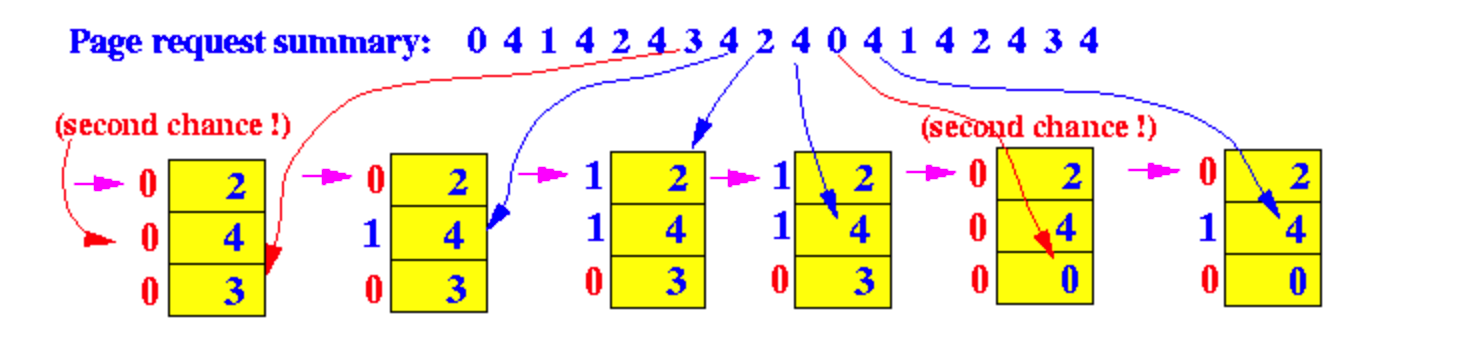
왼쪽부터 차례대로...
1) 프레임 내에 page3 없는데, page4 참조 비트가 1이므로 건너뛰고(second chacne) page1 참조 비트는 0이었으므로 교체되고 포인터는 다음칸으로 이동
2) 프레임 내에 page4 있으므로, page4 의 참조 비트를 1로 수정, 포인터는 그대로
3) 프레임 내에 page2 있으므로, page2 의 참조 비트를 1로 수정, 포인터는 그대로
4) 프레임 내에 page4 있으므로, page4 의 참조 비트를 1로 수정, 포인터는 그대로
5) 프레임 내에 page0 없는데, page2와 page4의 참조 비트가 1이므로 건너뛰고(second chance) page3 참조 비트는 0이었으므로 교체되고 포인터는 다음칸으로 이동
6) 프레임 내에 page4 있으므로, page4 의 참조 비트를 1로 수정, 포인터는 그대로
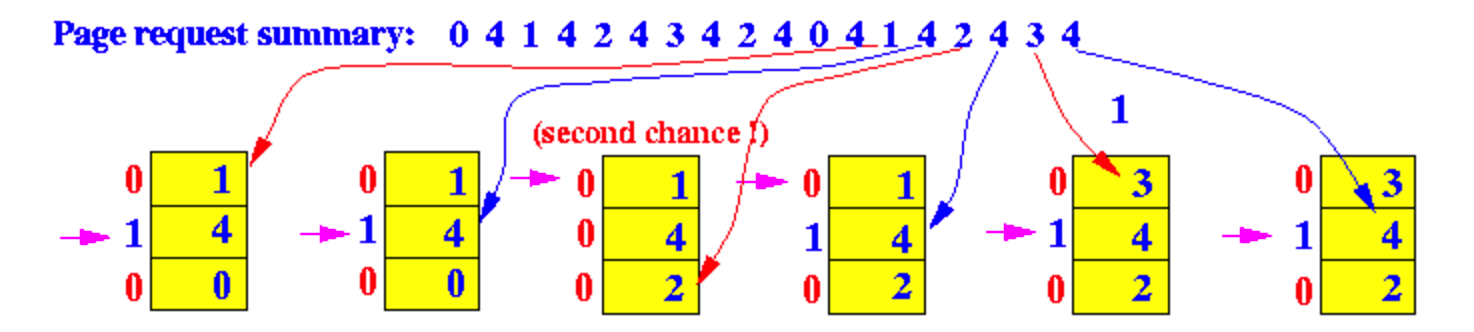
나머지는 직접 해보자. 위 과정을 잘 따라왔으면 어렵지 않게 해결할 수 있다.
4) Enhanced Second-Chance Algorithm
(참조 비트, 수정 비트)를 한 쌍으로 사용해서 Second-Chance 알고리즘을 좀 더 향상시킨 방법이다. 총 네 개의 쌍이 나오는데 값에 따른 의미는 다음과 같다. 교체되기에 적합한 페이지부터 차례대로 적었다.
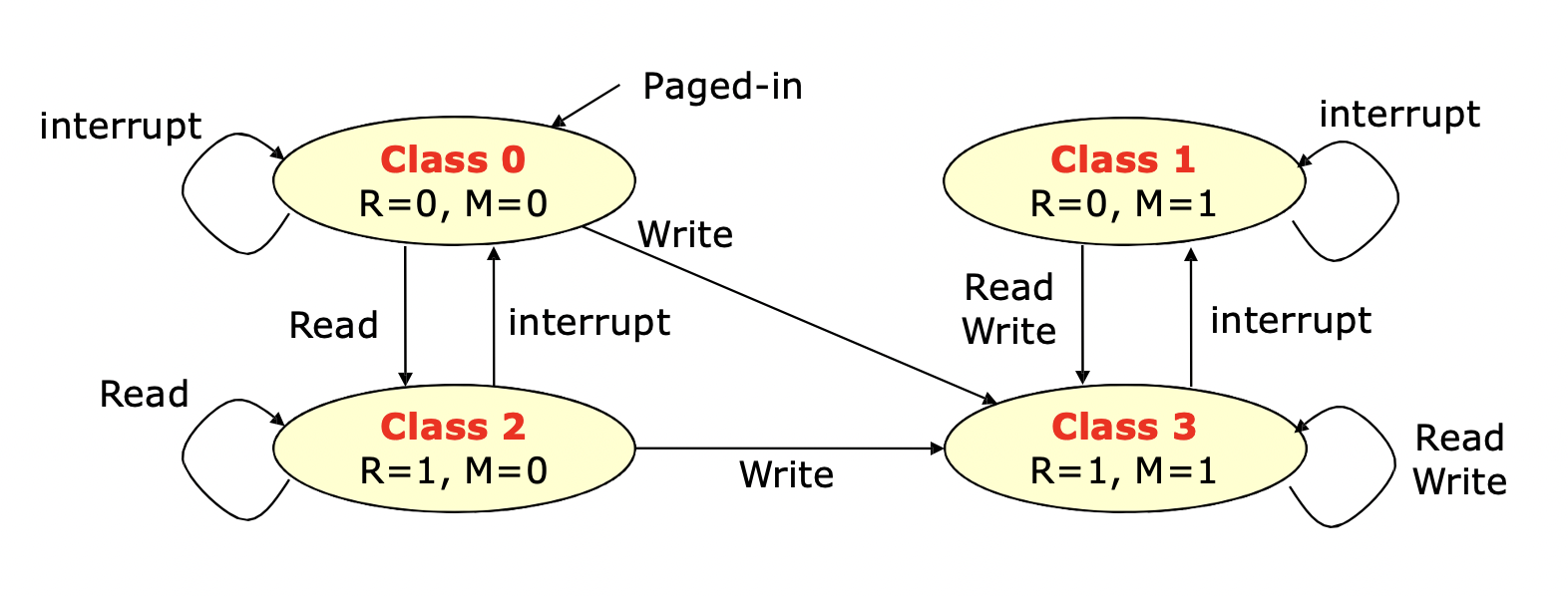
(Reference bit, Modify bit)
(0, 0) : 최근에 사용되지도 않았고, 수정되지도 않은 페이지. 교체하기 가장 적합한 페이지다.
(1, 0) : 최근에 사용되었지만 수정되지 않은 페이지. 다음 순환에서 교체될 가능성이 높다.
(1, 1) : 최근에 사용 및 수정된 페이지. 다음 순환에서 교체될 수는 있지만, 페이지를 디스크에 써야 한다(swap out).
(0, 1) : 최근에 사용되지는 않았지만 수정된 페이지. 교체하기에 좋은 페이지는 아니다.
4. Counting Algorithm
발생 빈도를 보고 교체하는 알고리즘이다. 가장 많이 사용된 페이지를 교체하는 방법과, 가장 적게 사용된 페이지를 교체하는 방법이 있다.
Least Frequently Used(LFU) Algorithm
: 가장 조금 사용된 페이지를 교체하는 알고리즘. 많이 안 쓰이니깐 덜 중요하다고 보는 관점.
Most Frequently Used(MFU) Algorithm
: 가장 많이 사용된 페이지를 교체하는 알고리즘. 조금 쓰인 것은 들어온지 얼마 안 된 뜨끈뜨끈한 페이지로 보는 관점. 방금 들어왔으니깐 더 있게 해주자는 마인드.
Counting Algorithm에서는 '각 페이지의 사용 빈도를 어떻게 구할 것인가?' 가 아주 중요한 이슈다. 이를 구해주는 알고리즘을 소개한다. 이름하여 Aging Algorithm이다. 이 알고리즘은 참조 비트를 이용해 각 페이지의 사용 빈도를 구해준다. 알고리즘 자체는 매우 간단하다.
Aging Algorithm 과정
가정 : 모든 페이지는 n비트의 참조 비트가 있다. n은 자기 마음대로 정한다. 모든 페이지의 참조비트를 0으로 초기화한다.
참조한 페이지의 MSB(최상위비트)를 1로 변경하고, 모든 페이지의 참조 비트 right shift. 끝!!!
참조 비트값이 가장 작은 페이지가 교체 대상이 된다.
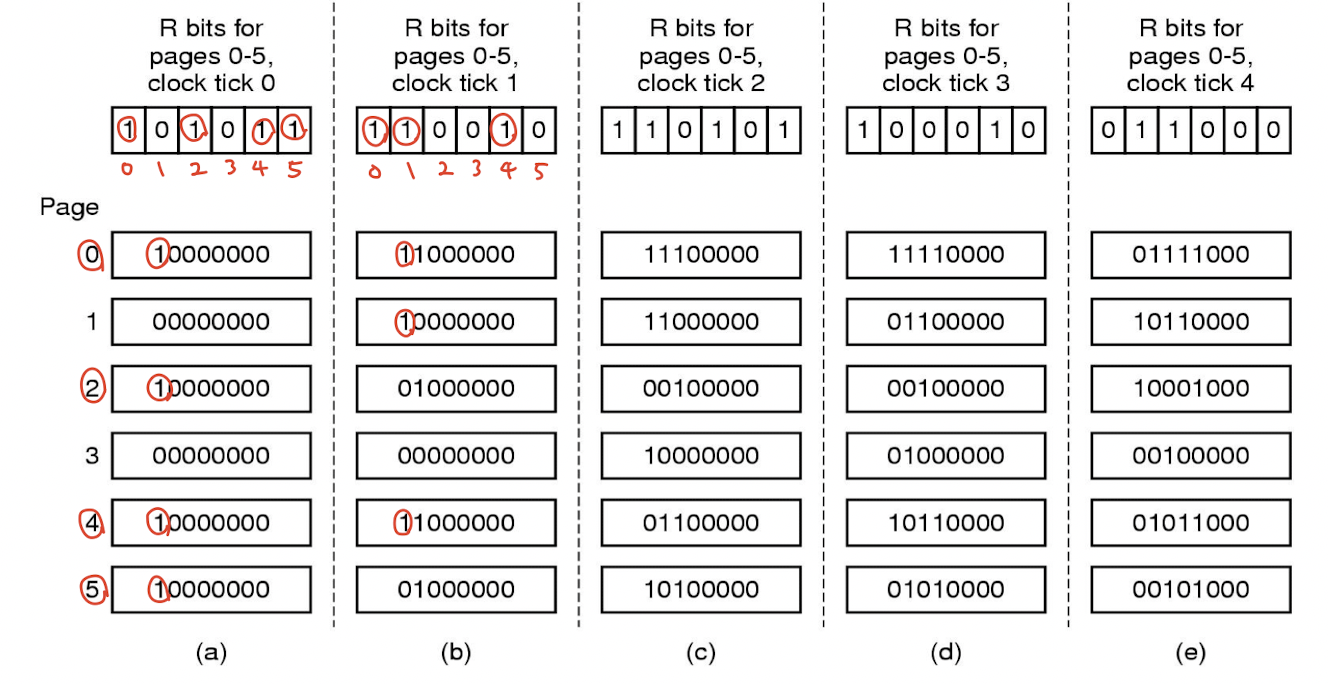
예제를 풀어보자. (a)와 (b)만 같이 살펴보자.
(a) - 참조된 페이지는 0, 2, 4, 5번 페이지다. 따라서 참조된 페이지의 참조 비트의 MSB를 1로 변경한다.
(b) - (a)의 결과에서 모든 페이지의 참조 비트를 right shift한다. 새롭게 참조된 페이지는 0, 1, 4번 페이지다. 따라서 참조된 페이지의 참조 비트의 MSB를 1로 변경한다.
참조 비트의 비트수는 몇 번의 참조까지 허용할지를 결정한다. 너무 많이 허용해버리면 그만큼 메모리를 잡아먹으니깐 적절하게 설정하는 것이 중요할 것 같다.
'메모리 계층 구조'부터 이 글까지 해서 길고도 길었던 메모리 내용을 끝낸다... 글 하나하나 작성하는데 정말 오래 걸렸다. 다음 글은 '파일 시스템'으로 다시 돌아도록 하겠다. 누군가에게 이 글이 도움됐으면 좋겠다.
'CS > 운영체제' 카테고리의 다른 글
| [ 운영체제 ] HDD 구조, HDD 스케줄링, SSD, 디스크 관리(Disk Management) (0) | 2022.02.24 |
|---|---|
| [ 운영체제 ] 쓰레싱(Thrashing)과 작업 공간(Working Set), 지역성(Locality) (1) | 2022.02.21 |
| [ 운영체제 ] 가상 메모리1 - Swapping, Demand Paging, Valid bit, Page Fault (0) | 2022.02.15 |
| [ 운영체제 ] 메모리 관리3 - 페이징 단점, 내부 단편화, TLB, 세그멘테이션(Segmentation) (0) | 2022.02.09 |
| [ 운영체제 ] 메모리 관리2 - 페이지 테이블의 세 가지 구조 (0) | 2022.02.08 |



