[ 운영체제 ] 메모리 관리3 - 페이징 단점, 내부 단편화, TLB, 세그멘테이션(Segmentation)
duqrlcks2022. 2. 9. 17:34
반응형
페이징은 외부 단편화 해결 방법으로 논리적 주소의 물리적 주소 사상을 불연속적으로 하는 메모리 관리 구조를 말한다. 그런데 이 세상에 완벽한 것은 없다. 득이 있으면 실도 있는법. 이번 글에서는 페이징의 세 가지 단점에 대해 소개한다. 그리고 각 문제의 해결책까지 살펴보는 것이 목표다. 우선 목차는 아래와 같다.
1. 내부 단편화 2. 메모리에 두 번 접근하는 문제 3. 프레임 내 데이터 종류 불일치 문제
1. 내부 단편화 (Internal Fragmentation)
외부 단편화는 주소를 연속적으로 할당해서 생기는 메모리 낭비였다. 이와 반대로 내부 단편화는 주소를 불연속적으로 할당해서 생기는 메모리 낭비다. 메모리 낭비가 생기는 이유는 '고정된 프레임 크기' 때문이다. 프레임 크기는 메모리를 읽기/쓰기 할 때 최소 단위가 된다. 즉, 프레임 크기가 4KB라고 가정했을때 Frame3이 1KB 공간만 사용중이면 나머지 3KB는 낭비되는 셈이다. 똑같이 총 N개의 프레임이 있다고 할때, 최악의 경우 모든 프레임이 1KB 공간만 사용중이면 3KB * N 만큼의 공간은 낭비되는 것이다. 아래는 내부 단편화를 아주 잘 나타내는 그림이다.
a-b-c 순서로 따라가보자.
a) 연속된 메모리 공간이 4KB 단위로 조각화 됐다.
b) Process A는 5KB를 필요로 한다. 따라서 두 개의 연속 프레임이 할당된다.
c) 8KB중 Process A에 의해 사용되는 공간은 5KB고, 나머지 3KB는 Hole로 존재하게 된다.
내부 단편화 때문에 페이지 크기 설정은 매우 중요한 문제다. 만약에 페이지 크기를 너무 크게 설정해버리면 그만큼 Hole의 크기는 커지기 때문에 내부 단편화가 심해질 것이다. 그러면 반대로 페이지 크기를 굉장히 작게 설정하면 어떻게 될까? 페이지 테이블의 엔트리 개수가 너무 많아져서 배보다 배꼽이 더 커지는 상황이 발생한다. 인텔 기준 페이지 크기는 일반적으로 4KB 또는 4MB로 설정한다고 한다.
내부 단편화의 해결책은 무엇일까? 내부 단편화는 주소의 불연속 할당이 원인이기 때문에 주소를 연속적으로 할당하면 해결된다. 안타깝게도 외부 단편화와 내부 단편화를 전부 해결해주는 방법은 없다. 연속 할당이 유리할 때는 연속 할당을 하고, 불연속 할당이 유리할 때는 불연속 할당을 하는게 최선이다. 그래서 나중에 이 두가지 방법을 모두 쓰는 구조가 나오는데, 이 글의 끝부분에 나오니깐 일단 넘어가자.
2. 메모리에 두 번 접근하는 문제
프로세스의 한 페이지가 메모리 프레임에 접근하기까지 아래의 두 과정을 거친다.
1. 페이지 테이블에서 자신의 프레임 번호를 알아낸다 (논리적 주소 → 물리적 주소) 2. 1번에서 알아낸 프레임 번호로 접근 (물리적 주소 접근)
우리는 페이지 테이블도 메모리 위에 있다는 것을 잊으면 안된다. 따라서 위 그림에 따르면 물리적 주소에 접근하기 위해서는 메모리를 두 번 거쳐야 한다. 그런데 메모리에 한번 접근하는데 걸리는 시간은 대략 100~400 CPU 싸이클이 소요되는데, 두 번 접근하면 CPU가 노는 시간이 그만큼 길어지게 된다. 그래서 실제 MMU는 약간 다르게 설계되어 있다. 메모리 계층 구조에서 CPU와 메인 메모리 사이에 '캐시'라는 저장장치가 더 있다고 했었다. 그렇다! 해답은 '캐시'에 있다. MMU는 메모리에 두 번 접근하는 문제를 해결하기 위해 TLB라는 특별한 캐시를 이용한다.
TLBs (Translation Look-aside Buffers)
TLB는 MMU 안에 내장된 캐시로 가장 최근에 참조된 페이지 테이블 엔트리만 저장해놓는다. 그러니깐 자주 쓰는 페이지 테이블 엔트리를 CPU와 가까운 곳에 둬서 CPU가 빨리빨리 쓸 수 있도록 하는 것이다. 그래서 이제 프로세스의 페이지는 자신의 물리적 주소를 얻기 위해 TLB에 먼저 접근하고, TLB에 자신의 물리적 주소가 있으면 해당 주소로 바로 접근하면 된다. 그런데 TLB에 자신의 물리적 주소가 없으면? 페이지 테이블(메인 메모리)까지 갔다온 뒤에 TLB에서 가장 오래된 엔트리와 교체한다. 무엇을 기준으로 교체하는지는 '가상 메모리'파트에서 자세히 다룬다. 이렇게 TLB에 자신의 물리적 주소가 있으면 'TLB hit'라 하고, 없으면 'TLB miss'라 한다.
TLB hit : TLB에 페이지의 물리적 주소가 있음 TLB miss : TLB에 페이지의 물리적 주소가 없음
CPU의 논리적 주소를 물리적 주소로 사상하는 과정을 그림으로 보면 아래와 같다.
TLB hit면 곧바로 물리적 주소로 접근할 수 있지만, TLB miss면 페이지 테이블을 한 번 거쳐야 한다. TLB는 페이지 테이블 엔트리를 저장한 캐시에 불과하기 때문에 위 그림과 같이 모든 엔트리는 'page number, frame number'의 정보를 가지고 있다. 그런데 TLB는 페이지 테이블과 약간 차이점이 있다. 페이지 테이블에서는 page number를 인덱스로 사용하지만 TLB에서는 page number를 인덱스로 사용할 수 없다. 왜냐하면 TLB에 저장되는 엔트리는 페이지 테이블의 일부분이기 때문이다. 따라서 TLB에서 page number를 찾을 때는 '탐색'을 해야한다.
TLB miss일 때를 좀 더 자세히 살펴보자. 우리는 메모리에 두 번 접근하는 것을 피하기 위해 TLB를 썼다. TLB hit일 때는 시간이 많이 단축되지만, TLB miss일 때는 오히려 시간이 늘어난다. 이유는? TLB에 접근하는 시간까지 낭비되기 때문이다. 그래서 TLB의 성능은 매우 중요하다. TLB의 성능 평가 척도로 'Hit Ratio'라는 값이 사용되는데, 이는 'TLB에서 page number 검색 성공 비율'을 뜻한다. Hit ratio와 메모리 접근 시간, TLB 접근 시간을 알면 메인 메모리에서 값을 가져오는데 걸리는 평균 시간을 구할 수 있는데, 이를 'Effective Access Time(EAT)'라고 한다. EAT식은 아래와 같다. 참고로 실제 제품들은 HIt ratio가 0.99에 근접한다고 한다.
memory access time = M TLB access time = T Hit ratio = α
Effective Access Time (EAT) = { α * (T + M) } + { (1 - α) * (T + M + M) } = { TLB hit 일때 메모리 접근시간 } + { TLB miss 일때 메모리 접근시간 }
ASID bits : Address space id, asid가 없으면 스케쥴링할때마다 TLB의 모든 내용을 flush해야한다.
C (Coherence bits) : 하드웨어에 어떻게 캐시되어있는지 판단
D (Dirty bit) : 페이지가 갱신되면 세팅
V (Valid bit) : VPN과 PFN이 유효한지
3. 프레임 내 데이터 종류 불일치 문제
이게 무슨 말인지 이해하려면 페이지 테이블 엔트리의 구성을 먼저 알아야 한다. 페이지 테이블 엔트리(PTEs)는 아래와 같이 구성되어 있다. V는 위에서 Valid bit와 일치한다. 위에서 다룬 것은 'TLB 엔트리'의 구성이고, 아래는 '페이지 테이블 엔트리'의 구성임을 헷갈리지 말자.
R (Reference bit) : 페이지 접근여부
M (Modify bit) : 페이지 갱신여부
Prot (Protection bit) : Read, Write, Execute 허용여부
여기서 Prot 비트에 주목하자. 데이터마다 보호 범위는 다를 수 있다. 그런데 페이지 안에 Read only, Write only 데이터가 공존하면 어떻게 될까? 페이징은 이런 문제를 해결할 수 없다. 왜냐하면 위 그림과 같이 페이지 단위로 Protection bit가 설정되기 때문이다. 또한 프로세스의 data 역역과 text 영역이 하나의 프레임에 같이 존재한다면? 프로세스 안에 있는 쓰레드는 text 영역을 공유하지만 data 영역은 공유하지 않는다. 그런데 프레임에 두 종류의 데이터가 공존하면 공유할 영역과 공유하지 않을 영역을 구분할 수 없다. 프레임 내 데이터 종류 불일치 문제는 이러한 상황을 말하는 것이다. 이에 대한 해결책이 바로 세그멘테이션(Segmentation)이다.
세그멘테이션 (Segmentation)
세그먼트(Segment)란 '일정한 크기의 연속된 주소 공간'을 뜻한다.
가상 메모리에서 세그먼트란 '사용자 관점의 논리적 데이터 단위'를 뜻한다.
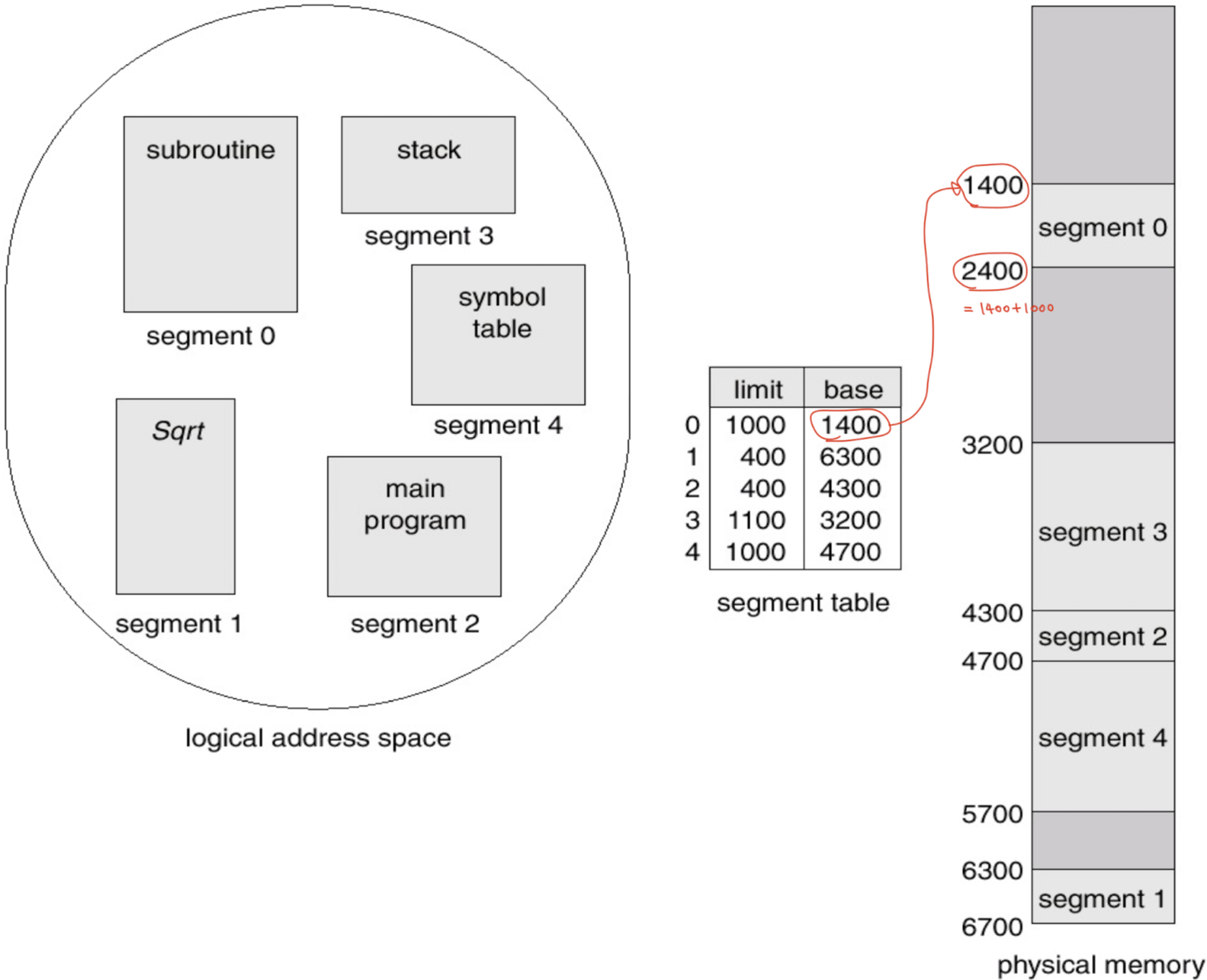
세그멘테이션(Segmentation)은 '가상 메모리를 논리적인 데이터 단위로 조각화 하는 것'이다. 쉽게 말해서 '사용자 관점에서 연관성 있는 코드 조각으로 분리'하는 것이다. 세그먼트는 'Main program', 'Function', 'Stack', 'Arrays'와 같은 논리적 단위이며, 프로그램은 세그먼트의 집합이라고 할 수 있다. 그림으로 보면 아래와 같다.
Logical View of Segmentation
위 그림과 같이 논리적 주소 공간에서 각 세그먼트가 갖는 크기는 제각각이기 때문에, 물리적 주소를 '고정된 크기'로 나눌 필요가 없다. 하지만 각 세그먼트는 물리적 주소에 불연속적으로 할당될 수 있다. 따라서 페이징과 마찬가지로 모든 프로세스는 각 세그먼트의 물리적 주소를 저장해주는 Segment Table이 필요하다.
세그먼트는 '연속 할당'을 잘 이해했으면 크게 어렵지 않다. 각 세그먼트는 물리적 메모리 안에서는 연속적으로 존재하기 때문에 메모리 보호를 위해 'base' 와 'limit' 값이 필요하다. Segment Table에 저장되어 있는 값이 바로 각 세그먼트의 base, limit 값이다. 그러면 세그먼트가 Segment Table에 어떻게 접근할까? 답은 논리적 주소에 있다!
페이징과 유사하게 논리적 주소는 <segment-number, offset> 으로 나눠진다. segment-number는 segment table의 인덱스로 사용될 수 있다. 원리는 page table과 동일하다. 그리고 Segment table도 메인 메모리 위에 있기 때문에 실제 물리적 주소를 찾기 위해서 Segment table의 시작 위치를 알아야 한다. 그래서 각 프로세스는 segment table의 시작 위치와 크기를 나타내는 값을 가지고 있는데, 이를 각각 Segment Table Base Register(STBR), Segment Table Length Register(STLR)이라고 한다. segment, segment table의 모습은 아래와 같다. 아래 그림에서 segment table의 0번째 인덱스의 실제 물리적 주소는 STBR의 값과 일치한다.
마지막으로 세그먼트의 장단점을 살펴보자.
장점 1. Easy to protect segments 같은 종류의 데이터 모음이기 때문에 Protection bit가 통일될 수 있다. 그리고 세그먼트 테이블의 base, limit 값으로 세그먼트끼리의 침범을 막을 수 있다.
2. Easy to share segments 서로 다른 프로세스의 세그먼트끼리 공유가 쉽다. 왜냐하면 segment table의 base 값을 같게 설정하면 물리적 주소의 값이 일치하기 때문이다. 아래 그림 참고!
3. No internal fragmentation 쓰는 메모리 공간만큼만 할당받기 때문에 내부 단편화가 발생하지 않는다. 하지만 이로 인해 외부 단편화가 발생할 수 있다.
단점
1. Cross-segment address 같은 프로세스의 세그먼트끼리 데이터 공유가 어렵다. 왜냐하면 논리적 주소의 segment number로 segment table의 인덱스가 결정되기 때문이다.
2. Large segment tables Segment table이 메모리 공간을 차지하는 문제가 발생한다. 페이징과 동일하다.
3. External fragmentation 쓰는 메모리 공간만큼만 할당받기 때문에 외부 단편화가 발생할 수 있다.
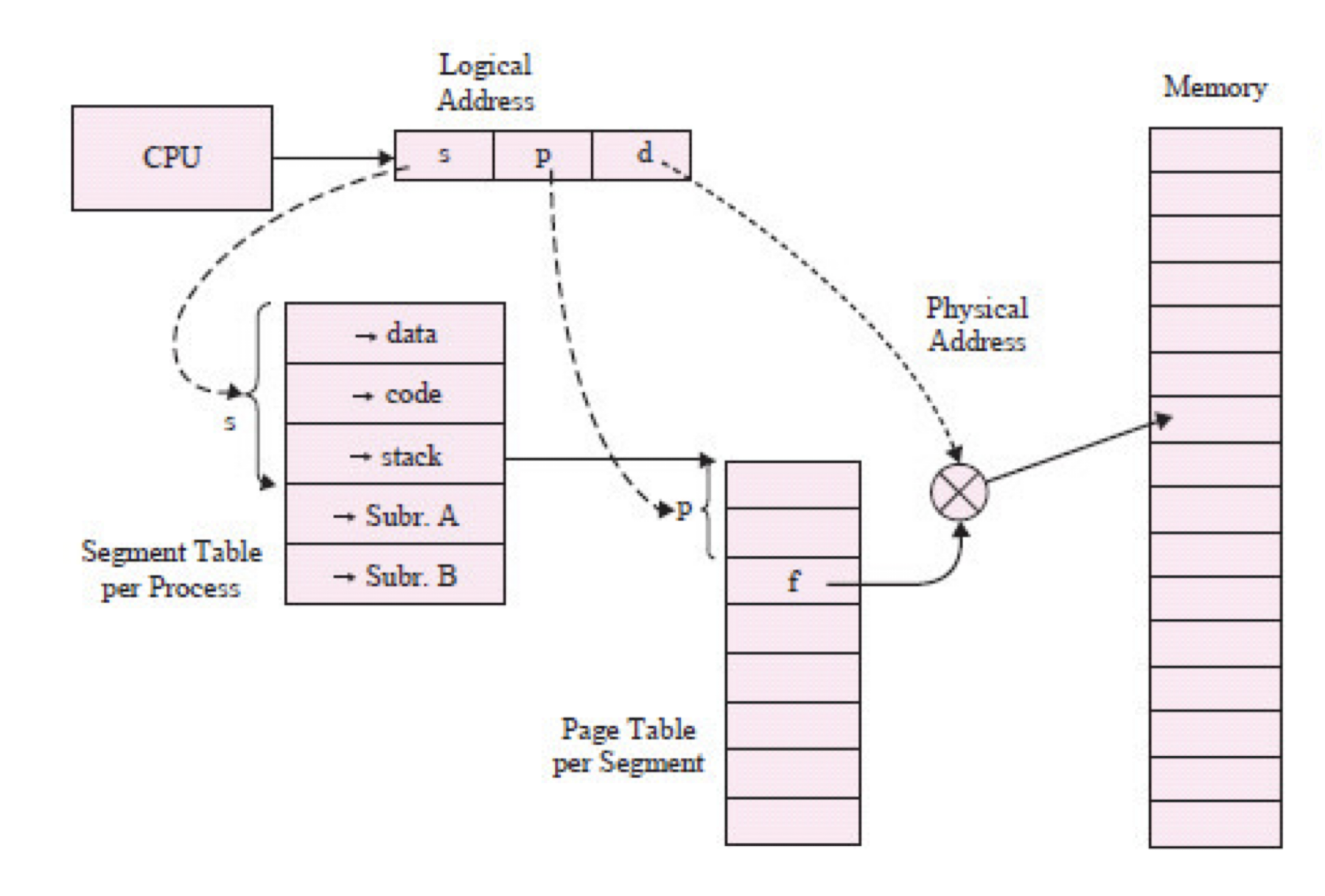
Hybrid Approch (Paging + Segmentation)
페이징과 세그멘테이션은 각각 장단점이 있다. 각각의 장단점을 최대로 활용하기 위해 두 방법을 동시에 사용하는 방법이 있다. 최초의 논리적인 단위는 Segmentation을 쓰고, 각 segment 안에서는 Paging을 쓰는 방법이다. 각 세그먼트는 자신만의 페이지 테이블을 가지게 되고, 논리적 주소는 먼저 세그먼트에 접근한 뒤에 다시 세그먼트의 페이지 테이블에 접근하는 것이다. 그림으로 보면 아래와 같다.
MULTICS Address Translation Scheme
여기까지 '메모리 관리' 파트를 마무리 한다.. 다음 글부터는 '가상 메모리'로 다시 돌아오도록 하겠다.